
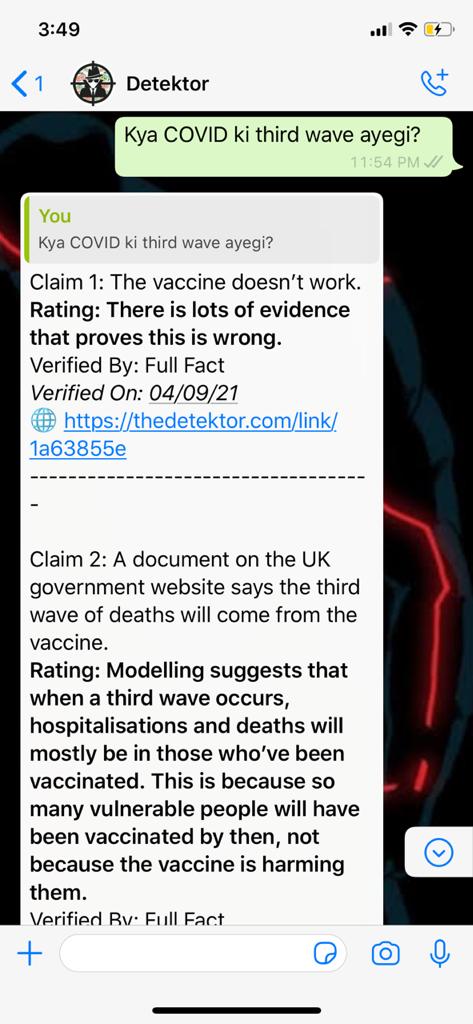
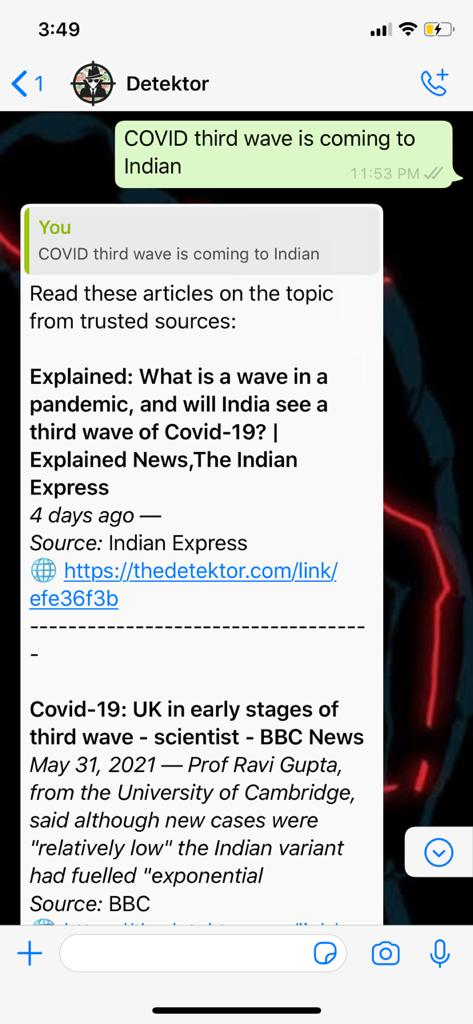
According to a recent survey done in the UK, 59 percent of the subjects had come across fake news on COVID-19 (the subjects being from, 16 to 24-year-old). It only gets worse in India. A skim through a handful of reliable sources, seems to be an effective solution (to the possible misinformation spread). But, unfortunately, the middle-aged population of our country, isn’t as comfortable with technology, and is largely unaware of the credibility of the sources they come across. This leads to the propagation of misinformation at an exponential rate, especially if the information has a ‘shock’ element to it. Chinmay Singh, a 5th-year undergraduate at IIT Kharagpur, saw his parents in confusion and panic due to such forwards, when he contracted the Corona Virus. He thus decided to make ‘Detektor’ with his friends Yash Khandelwal, Nikhil Shah, Apoorve S., Harsh Sah. ‘Detektor’ is a Whatsapp chatbot, which takes a ‘claim’ from you, in text (this text is termed as the 'query'), and responds on the credibility of the same. Currently, there are two formats of the responses which are supported. In the first category, a ‘conclusion’ is presented, clearly stating if the news (claim) has been confirmed to be ‘false’/’true’. In the other format, a list of articles (with respective links) is sent to the user for reading and confirmation, to handle the case when a ‘claim’ can’t be accurately classified as ‘true’/’false’ (keeps the possible ‘false-positives’ in check). Now we’ll look under the hood, on how the ‘Detektor’, ‘detects’ fake news.
So Many Languages
‘Detektor’ supports all Indian languages;along with mixed ones like ‘Hinglish’. To make it work for so many different languages, firstly all the languages are converted to ‘English’, using prevalent Machine Learning techniques. Machine learning techniques are algorithms, which don’t need to be explicitly ‘told’ what to do, but are programmed such that, they can ‘learn’ with ‘experience’ (they change to get closer to the true outputs, that process is called training). "This translation ensures that all the further processing and analysis logic can be the same for all of the languages.", explained Chinmay.
Processing ‘Language’
After the ‘translation’, text in English. The first thing to do now, is to ‘isolate’ the ‘claim’ to be verified. For example, a ‘text’ sent to the bot is “Mr. X who is the CEO of ABC corporations, and was accused of a crime ‘Y’ a few weeks back, died in a car accident yesterday.”. A lot of information is contained in the above sentence, but the only relevant part is, “Mr. X died in a car accident yesterday.”, (the claim), a search can be done only when this is ascertained. This is called ‘summarizing’ and many ML algorithms are written for the same. Not just any off-the-shelf ‘summarizer’ can be used for this purpose, as they’re not programmed with the specific aim of ‘claim-isolation’ in mind (and thus won't be as effective, in a problem this specific). According to Chinmay, ‘Summarization’ is the current bottleneck of the pipeline. As most of the ‘well-trained’ (trained with a lot of data) ML models available, are not specific to the problem at hand. This bottle-neck is the reason why there’s an upper limit at the number of words in a ’query’, and why the effectiveness drops significantly with the increase in the size of the 'query'.
The current version doesn’t support multimedia, although there are effective ‘OCR’ algorithms (Optical-Character-Recognition, used to recognise text from photos). The reason being, photos and videos, a lot many times contain details like names, numbers, watermarks and dates. Which can make ‘summarization’ even less accurate, elevating the risk of ‘false-positives’.

The Search
The list of sources for validation is maintained manually, to ensure that no ‘shady’ or ‘polarized’ sources make it into the list. International standards of fact-checking are upheld, and sources are the ones, verified by organisations like the IFCN (International Fact Checking Network).
The isolated ‘claim’ searched for, across the articles. And one of the two aforementioned responses is sent to the user. Chinmay pointed out, that the relevant part of the article can be extracted efficiently, using Deep Learning techniques. But this hasn’t been applied, as its effect on the accuracy is yet to be tested and confirmed, (to avoid false-positives).
The API
Chinmay pointed out, that the ‘Detektor’ currently uses many 3rd party and open source APIs to achieve its functionality. An API can be understood as a program connecting 2 logics (programs) running on 2 different systems, the output of one is used as an input for another. Like our input on Google search is taken by the application on our computer, an API connects it with Google’s severs, which take input from the application, and use the ‘search-function’ for searching through the database and find an output, then the API returns the results (the output of search) to us. "We are trying to get the Whatsapp Business API, it will make the program more straight-forward to manage, although it will add to the costs we’re incurring", states Chinmay.
When asked about the current work, Chinmay stated that work is ongoing on the 'summarization' bottleneck, and on including multimedia support for queries. One of the features they’ll be working on in near future is, including a personalised ‘Fake-News’ feed, which alerts the user to possible fake-news they may have come across, depending upon their Geographical location and other factors. This will require personal data of the user, for which they’ll ask for relevant permissions.
Other aims that Chinmay pointed out are, making the bot reach more of the target audience, the creators plan on using Whatsapp and news agencies to create awareness about the project. When they have a large enough user-base, and have satisfactorily dealt with the current issues and bottlenecks, they’ll open-up donation platform to deal with the finances of the project (as aforementioned, the project is self-financed as of now). When asked if he wishes to commercialize the project in coming time, Chinmay stated,
“It’s a problem, we wish to solve, and commercializing will not achieve that. We can put out a model right now, but the people won’t benefit.”
. And thus, the war against misinformation and fake news, wages on!
