
Introduction
With our need for faster and errorless computing, several techniques have been applied. They have their uptakes and down takes. One of the prominent and efficient techniques is Distributed Computing. Distributed Computing distributes the task over multiple computers which makes this approach faster and more tolerant to system failures that is if any systems shuts down due to any internal or external factors the whole task is not delayed.
Distributed Computing uses multiple different systems which have distributed memory. When a program is run in a distributed system, the systems requires to share data with each other just like a team working together. Data is shared at multiples instances by passing messages from one system to another. When different systems try to access a same variable/memory on a system, we get a race. This race occurs when there is a confusion between systems and different systems try to rewrite same memory. For example in a team if a person changes any notes for their easiness but other person later misinterprets the information we would call it a race. This eventually leads to the failure of the program as the program either entirely stops or performs differently from what is required.
When a race occurs, there is no way to correct it. Unlike a team of humans, computers can not have a 'feel' that something might be wrong. Computers continue with whatever information they get as their information is limited to constants and variables. Since we can not correct a race we have to predict when a race may occur in a program and try to avoid it by making sure no two systems try to write on a same variable at the same time and making sure there is some time interval so every system can share information without confusing it.
Async Finish Programs
Async Finish Programs are programs with an asynchronous finish. When an async finish program is run in a distributed system the task spawns single or multiple child tasks. Task which require spawning of a child task is called parent task. It is like when a team of humans are doing a task and a person (let it be A) finds their task to be too lengthy so they divide task into two parts and ask another person (let them be B) to help with one part. Now B might ask another person for help depending on how difficult their part of the task is. At the end of the program, everyone combines their result into a combined result.
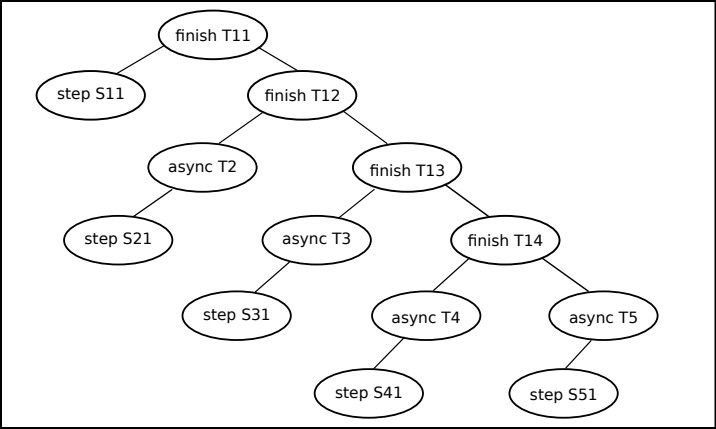
When a parent task spawns a child task it is called a node in the structure tree (structure tree is a visual representation of task distribution and creation of child tasks). These nodes are critical points for the races. There are three types of nodes: Async Node, Finish Node, and Step Node depending on how they run with the parent task.
An async node is where child tasks and parent tasks execute simultaneously, that is meanwhile parent task is running on a system other part of it is running on another system at the same time. Finish node is where the parent task has to wait for the child task to finish and then start on their own work, that is system waits for results of child task to continue working on parent task. Step node is a maximum sequence that can run without task management, that is maximum task that can be completed separately from parent task.
Vector Clocks and their Use
Vector Clocks are an algorithm to detect causality violations/ races in distributed systems. Vector Clocks works by recording increment in each process’s scalar clock with respect to other scalar clocks.
To understand it in a better way, vector clock is like a mental ability question/ riddle that you must have tried to solve, about a giant round table with 9 people sitting on it where A is on immediate left of B and there are 4 people between B and C.
All the systems have their own scalar clocks and there is no need for their scalar clocks to be in sync. System knows when it tried to access a variable but how do other systems know about it? For this, every time that variable is reached a little information along with information for the task completion is passed.
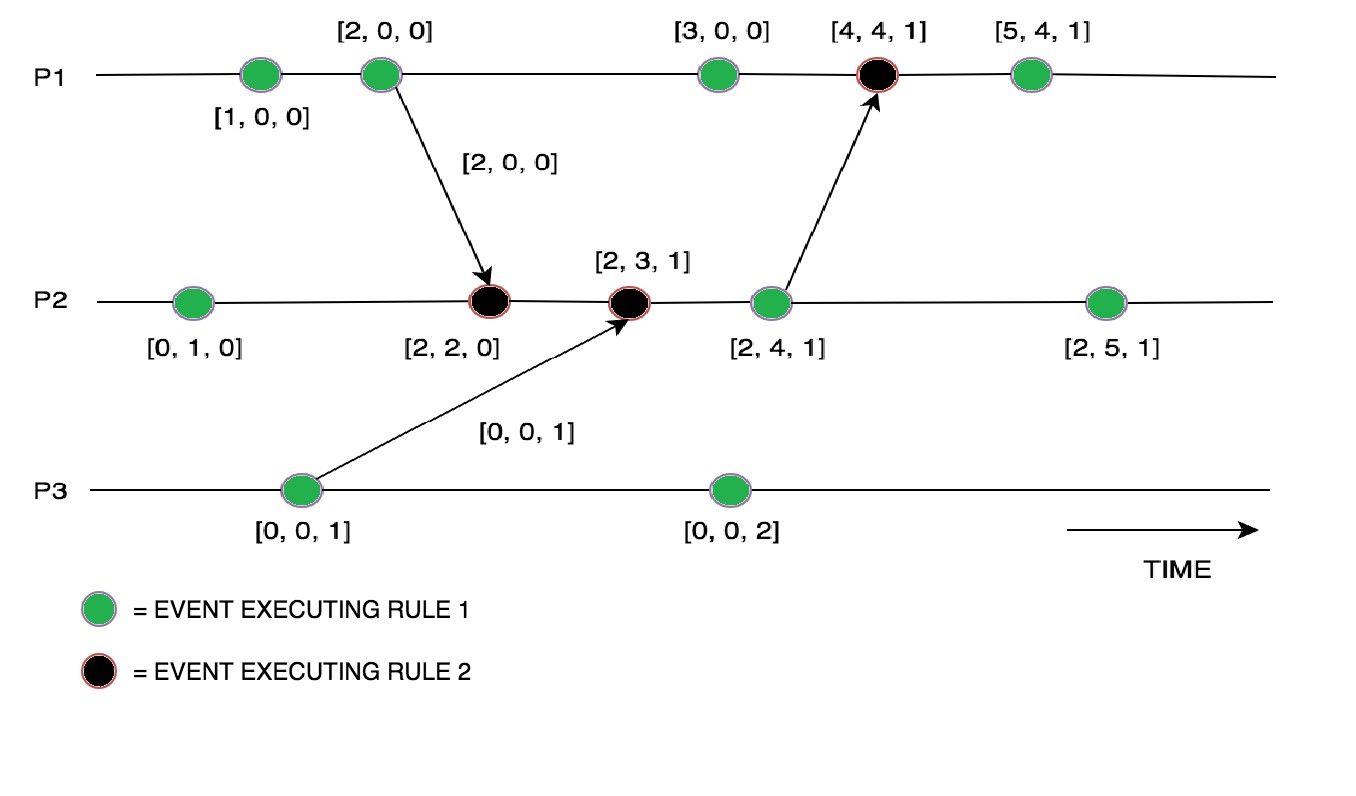
Let there be a task named P. Task P has three different Processes going on that work together to achieve the completion of P. Each Process has its scalar clock and a vector clock to hold values of a scalar clock of other processes as well. Initially, no work has been done and hence the scalar clock of all Processes is set to zero. Every time an event occurs at a process, its scalar clock gets an increment of 1. Every time a message is received by a process its scalar clock gets an increment of 1, as well as the vector clock in this process’s memory, gets set to what is received if it is greater than what is stored in the Process’s memory (arrows denotes passing of a message between two processes).
FastTrack is an earlier work that used Vector Clocks for race detection. FastTrack realized Vector Clocks was an expensive algorithm in the sense of memory. It also realized how full generality of vector Clocks is not required in over 99% of cases and therefore tracked only the last writer, or in some cases, last reader data. It further alternated between epoch and vector clock forms. This approach worked well with multithreaded functions but didn’t go well with task-based programs.
FastRacer also realizes the huge memory Vector Clocks uses. The program tackles it in three different ways.
First, by tracking read-only clock entries. FastRacer’s insight is that many child task’s vector clocks in the programs go unchanged with respect to that of their parent task. Storing these vector clocks only takes up the memory reducing the efficiency. To use their findings, each task is given a read-only and a read-write vector clock. Child tasks then contain a reference to read-only vector clock of the parent tasks instead of redundant copies.
When a new child task is spawned, FastRacer first checks the size of the read-write vector clock of the parent task. If it is greater than a threshold then the parent task’s read-only and read-write vector clock is merged and assigned to the child task’s read-only vector clock while its read-write vector clock is kept empty. If it is less than the threshold the child task’s read-only vector clock points to the parent task’s read-only vector clock, and the parent task's read-write vector clock is copied to the child’s read-write vector clock.
Second, by Optimizing Vector Clock Join. After a child's task finishes it joins with its parent task. Fastracer finds that it doesn’t need to store Vector Clock data for child tasks after they join with their parent tasks. Instead tracking the child tasks joining with parent tasks would suffice.
Third, by Vector Clock Caching. Some Vector Clocks can still take much space even after optimization. FastRacer here caches vector clock values and uses the map data structure representing vector clocks.
Most of the prior works have overlooked the use of Vector Clocks in Race Detection. FastTrack is a work that have used vector clocks but it had compromised full usage of Vector Clocks. FastRacer uses structured execution of Async Functions to its advantage and out performs FastTrack in race detection for task-based async functions.
With more efficient Race detection program Distributed Computing becomes more fast with lesser probability of a race occurring and task failing. With no systems failing it will be much faster but more importantly it will be more fail proof. There are many real life examples where most of the operation is based on the computer programs and a single error can lead to mission failure. We are trying to reduce these loses to almost zero and this is where FastRacer helps us.
